データベースのdumpをS3などのストレージサービスへ格納するとき、Data Pipelineなどのデータ転送サービスを使用するのが常套手段だと思います。
しかし、LAMP環境でDBからdumpを出力、ファイルに保存し、そのファイルをストレージサービスへアップロードと保管することもあると思います。
このとき、EC2に十分な空き容量がないとdumpを取得できませんよね。 コマンドのパイプラインをうまく利用すると、EC2の容量を食うことなく、直接ストレージサービスへアップロードすることができます。
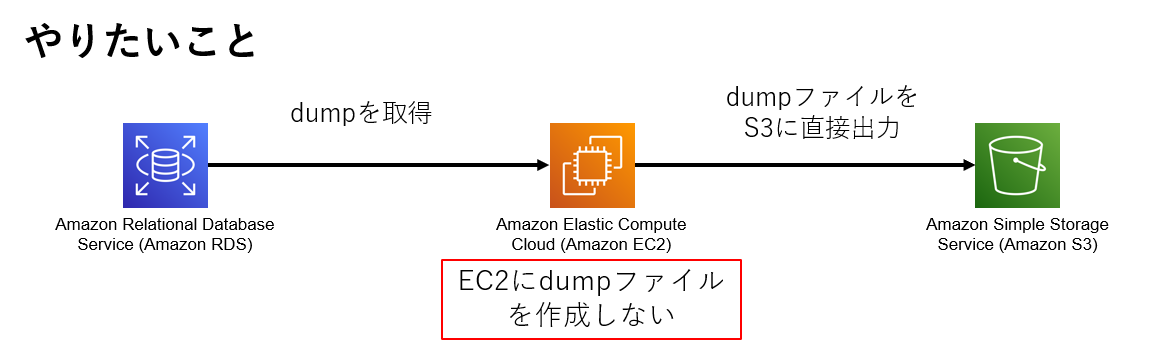
RDSのdumpを直接S3へ出力する
RDS,S3両方にアクセスできるEC2で以下のコマンドを実行する例です。
mysqldump -p -u <USER> -h <DB-instance-identifier>.rds.amazonaws.com <database> <table> | aws s3 cp - s3://<bucket-name>/<dumpfile>.sql
dumpをgzip圧縮し、S3へアップロードする際のコマンド例です。 mysqlのレコードを出力しつつ、gzip圧縮しs3へ格納します。
mysqldump -p -u <USER> -h <DB-instance-identifier>.rds.amazonaws.com <database> <table> | gzip | aws s3 cp - s3://<bucket-name>/<dumpfile>.sql.gz
S3からdumpを直接RDSへインポートする
RDS,S3両方にアクセスできるEC2で以下のコマンドを実行する例です。
aws s3 cp s3://<bucket-name>/<dumpfile>.sql - | mysqldump -p -u <USER> -h <DB-instance-identifier>.rds.amazonaws.com <database> <table>
gzip圧縮されたdumpファイルをRDSへ直接インポートする際のコマンド例です。
aws s3 cp s3://<bucket-name>/<dumpfile>.sql - | zcat | mysql -p -u <USER> -h <DB-instance-identifier>.rds.amazonaws.com <database> <table>
所感
ローカル (この場合はEC2)にdumpファイルを作成せずストレージサービスへdumpを格納する方法を紹介しました。圧縮する場合はCPU、メモリに負荷がかかります。また、S3に保存する場合はRDSのスペックに依存します。
データベースが大きい場合はデータ転送サービスの利用をお勧めします。